深圳计算科学研究院科研团队2篇论文成果,近期在数据库领域国际顶会SIGMOD(Special Interest Group on Management Of Data)发表,题为“A Hierarchical Contraction Scheme for Querying Big Graphs”“Parallel Rule Discovery from Large Datasets by Sampling”。相关研究成果对于实现高效大规模图计算以及大规模数据集的规则发现,分别提供了创新有效的解决思路。
A Hierarchical Contraction Scheme for Querying Big Graphs
需要耗费高昂成本及大量资源是大规模图计算面临的重大挑战之一。如果能在资源有限的条件下实现大规模图数据查询,将有力促进大规模图计算技术的应用,帮助企业降本增效,并满足移动设备、安全计算等资源有限条件下的计算需求。
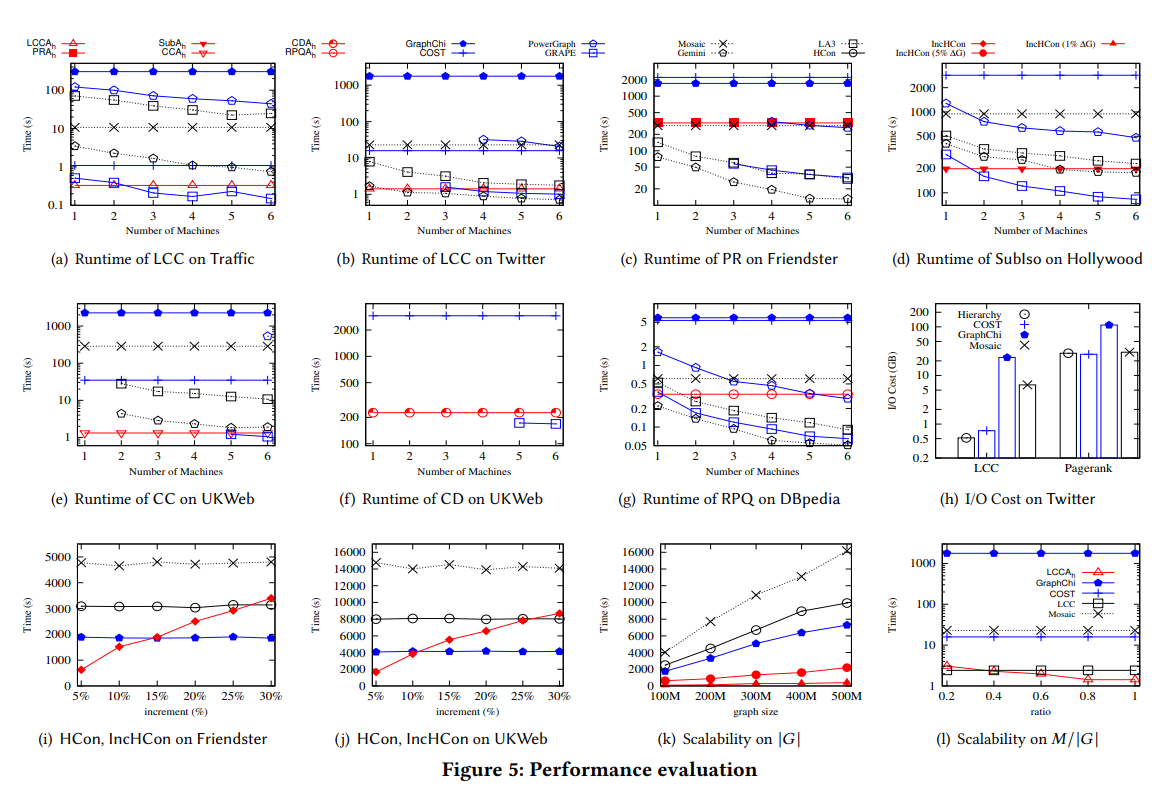
为此,我院科研团队提出了一种用单机查询大规模图数据的分层压缩方法。该方法创新性地将常规结构迭代压缩为超节点,并建立了一个可压缩图数据的层次结构,直到某一层级的压缩图能够被完全放进内存。对于每个使用中的查询类Q,超节点携带了概要SQ,Q的查询在可行情况下通过使用SQ来回答,否则就钻取到层次结构的下一层级并将图数据解压至有限大小。
为了适应层次结构,我院科研团队将现有的各种顺序(单机)算法中的逻辑和数据结构重复再利用。为了维护层次结构,还提出了一种有界的增量算法,使其成本只由输入和输出的变化大小决定。
通过使用真实数据和合成数据实验验证,在单机内存小于图数据的7.6%时,层次计算结构不仅能精确得出查询答案,还能将各种应用程序的速度平均提升9.8倍,甚至比使用6台机器的并行图系统快120.1倍。
阅读原文:
https://dl.acm.org/doi/10.1145/3514221.3517862
Parallel Rule Discovery from Large Datasets by Sampling
规则发现被研究者视为几十年以来的长期挑战。从大规模数据集中发现规则往往成本高昂,当规则被定义在多表中时,成本问题更加惊人。
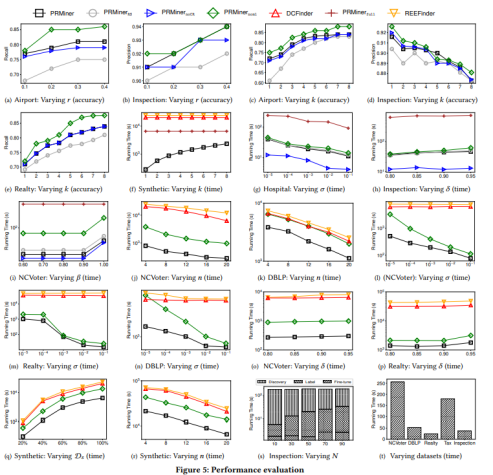
为此,我院科研团队创新性地提出了一种多轮抽样策略来发现实体增强规则(REEs)。该规则支持常数模式和机器学习谓词,可用于跨表实体解析和冲突解析。假设给定精度上界𝛼和召回率上界𝛽,该多轮抽样策略可提供如下保证:精度保证,即从样本中发现的有效规则至少占比𝛼%;召回率保证,即全数据集上𝛽%的有效规则可以从样本中挖掘出来。
我院科研团队还量化了样本上规则的支持度、置信度与整个数据集上的对应关系。为了与跨表规则中元组变量的数量相适应,采用深度学习Q-learning来选择语义相关的谓词。为了提高召回率,还开发了一种基于模板的方法来还原数据集中的常数模式。通过对该算法进行并行化处理,从而保证在使用更多处理器时减少运行时间。
基于真实数据和合成数据实验验证,该方法在样本率仅为10%的情况下,可将REE发现速度提高12.2倍,召回率达到82%。
阅读原文:
https://dl.acm.org/doi/10.1145/3514221.3526165
数读SICS科研:
截至2022年9月下旬,研究院共发表/录用高水平论文74篇,其中CCF A类61篇。申请知识产权共48项;其中申请专利/PCT共43项、授权发明专利5项;申请并授权软件著作权5项。
