当地时间8月16至20日,数据库国际顶会——第47届VLDB 2021(Very Large Date Bases)在丹麦哥本哈根召开。深圳计算科学研究院(以下简称“深算院”)科研团队及其合作者的4篇论文在大会上发表。这4篇论文分别在解决实体解析和冲突解析、单一来源SimRank查询以及大规模图计算等多个大数据重难点问题上,取得了领先性和突破性的创新成果。
一、论文标题:
《Parallel Discrepancy Detection and Incremental Detection》

*Parallel incremental algorithm PIncDet
实体解析(entity resolution)和冲突解析(conflict resolution) 一直是全球数据质量研究的长期挑战,其中, ER是判断哪些数据是同一个实体, CR是解决同一实体中存在的语义冲突,语义冲突和不匹配的实体往往共存并且内在地互相干扰。如何在同一个数据查错和增量查错过程中捕捉冲突并识别实体?深算院科研团队及其合作者在论文中,开创性地提出一种统一逻辑规则和机器学习模型的方法,通过该方法能够发现数据中的冗余、错误匹配和冲突,为解决ER和CR问题开辟了新思路。经真实数据集和基准测试,该方法在准确率上分别比基于逻辑规则和机器学习模型的方法高33%和36%,同时比ER和CR单独的检测算法分别高31%和41%,经实验证明具有广阔的理论和应用前景,未来可广泛应用于电商、电信、金融反欺诈等多个领域。
论文链接:
http://www.vldb.org/pvldb/vol14/p1351-tian.pdf
二、论文标题:
《DISK: A Distributed Framework for Single-Source SimRank with Accuracy Guarantee》
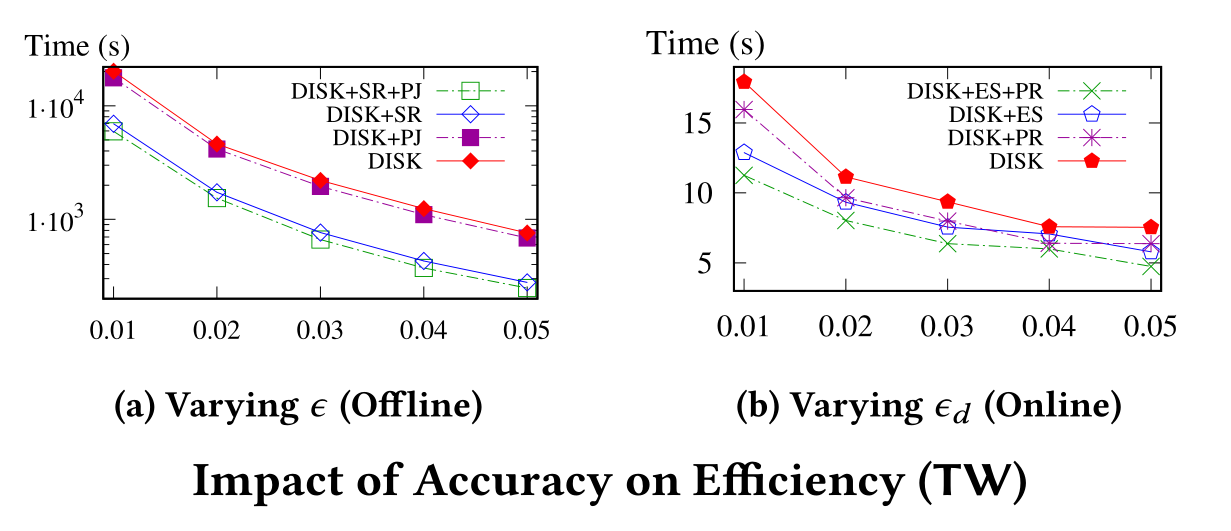
目前,处理和分析大规模的图数据已成新信息时代的必然趋势,其中数据对象间的相似性度量在数据分析和挖掘中起着关键作用。业界提出的几种基于链路的相似性度量方法中,单一来源的SimRank前途广阔,被广泛应用于社交媒体的朋友推荐、推文、群组等应用中。但由于内存和并发性的限制,高效处理大型图问题已超出了单机能力,现实中不论是从理论还是实验结果来看,在分布式环境中有效处理单一来源SimRank查询不仅重要而且充满挑战。对此,深算院科研团队及其合作者开创性地提出了一个分布式框架DISK,用于处理单一来源SimRank查询。在该框架下,还提出了不同的优化技术来提高索引和查询的效率。实验证明,DISK可以扩展到数十亿个点和边的图规模,并能在几秒内回答确保精确度的在线查询。
论文链接:
https://dl.acm.org/doi/10.5555/3430915.3442434
三、论文标题:
《GraphScope: A Unified Engine For Big Graph Processing》
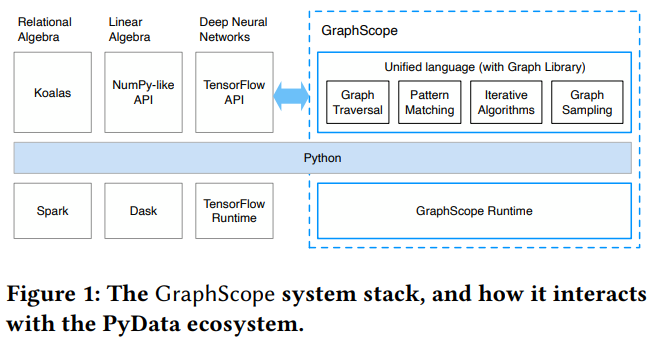
目前,在现代数据密集型应用程序的开发中,具有高级语言支持能力的分布式执行引擎,如Koalas、Dask和TensorFlow已被广泛采用并取得巨大成功。但若想要对异构数据进行更深入的分析,从而进一步解决更重要的问题,往往需要使用涉及图计算的分析工具进行替代,比如在产品和广告推荐中经常用到的算法,都属于对图数据的深度学习。然而现实中的图应用往往更为复杂,单个工作负载中经常交织着多种类型的图计算系统,这些系统可能具有各不相同的编程模型和运行时间,从而产生多个系统中的数据表示、资源调度和性能调整等多类问题。
针对以上难点,深算院科研团队及其合作者提出了一个能与其他数据处理系统无缝对接、通用的大规模图计算处理引擎—GraphScope,该引擎提供了一个强大而简洁的声明式编程接口,并支持在通用数据并行计算系统中无缝整合高度优化的图引擎。实验证明,GraphScope的性能优于许多最先进的图系统。
论文链接:
http://vldb.org/pvldb/vol14/p2879-qian.pdf
四、论文标题:
《GraphScope: A Unified Engine For Big Graph Processing 》
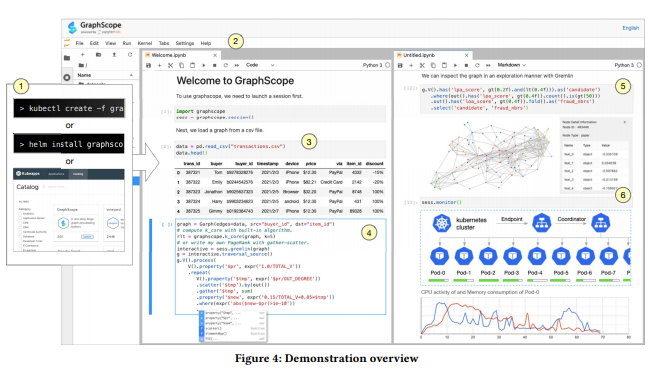
目前,图计算被广泛应用在互联网、金融等互联网领域。比如在电子商务平台上,一些卖家可能会协同买家进行欺诈性交易和评论,针对这类行为,通过整合各种图算法,能够更好地捕捉欺诈行为的协作性质,从而进行欺诈检测。然而在现实中,随着不同图处理系统的整合,出现了以下问题:现有的图处理系统通常是为特定类型的计算设计的,其抽象编程模型和运行时可能非常不同,这给编程带来了很大挑战;许多系统(例如Apache Giraph)需要对底层的抽象编程模型有深入理解,这使得只有图计算专家才能进行图计算;与其他系统(如Spark)的互操作通常涉及过多的数据转换和移动,这可能会大大弱化整个执行性能。
针对上述难点,深算院科研团队及其合作者开创性地提出了一站式大规模图数据处理系统GraphScope,旨在为不同种类的图计算任务提供一个一站式的高效解决方案,大大降低了图计算门槛。同时,GraphScope的性能遥遥领先于同类系统,经实测GraphScope在万亿规模的海量图数据上实现了2.86倍的速度提升,并被证明在风控、金融反欺诈等多个关键互联网领域,能实现重要的业务新价值。
论文链接:
http://vldb.org/pvldb/vol14/p2703-xu.pdf
